Hibernate[三]
2019-11-01 / JAVA / 1542 次围观 / 0 次吐槽 /Hibernate实体状态回顾

1、Hibernate的多表关联关系映射
1.1、多对多的关联关系映射
² 目标:掌握如何对多表关联的映射进行配置
² 以学生和课程为例,一个学生可以对应多个课程,多个学生可以对应一个课程
1.1.1 学生和课程的JavaBean(entity,pojo,model)

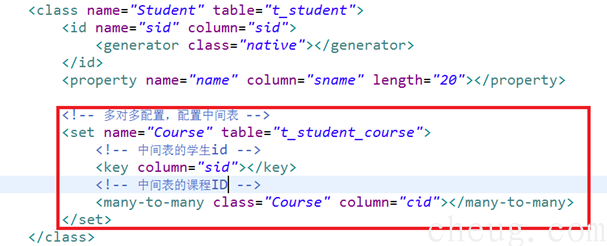
1.1.2学生和课程表的hbm.xml映射
Student.hbm.xml
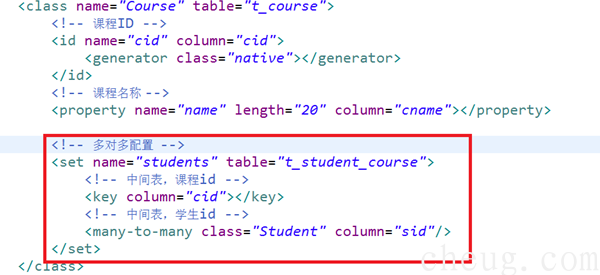
Course.hbm.xml
1.2、多对多的测试
1.2.1 自动生成三张表
public void test1(){
Session session = HibernateUtils.openSession();
session.beginTransaction();
session.getTransaction().commit();
session.close();
}
1.2.2 保存一个学生
l 注意保存前的外键维护和级联是如何的配置
l 一般操作多的一方选择级联,这里学生操作比较多
@Test
public void test1(){
/**
* 保存多对多数据
*/
Session session = HibernateUtils.openSession();
session.getTransaction().begin();
//1.创建2个学生
Student stu1 = new Student("特朗普");
Student stu2 = new Student("普京");
//2.创建2个课程
Course c1 = new Course("维护世界和平");
Course c2 = new Course("外贸");
//3.绑定课程到学生
stu1.getCourses().add(c1);
stu1.getCourses().add(c2);
stu2.getCourses().add(c1);
stu2.getCourses().add(c2);
//4.保存
/**
* 保存的注意事项
* 1.配置级联保存,只保存学生对象
* 插入2个学生,插入2两课程,中间4条,8条sql
* 2.如果在Student配置inverse="true",由Course来维护外键关系,中间表没数据
* 3.默认Student配置inverse="false",由Student来维护外键关系,中间表有数据
* 4.多对多,inverse不能两边都为true,如果两边都为true,不管保存哪个对象,中间表都没有数据
*/
/*session.save(stu1);
session.save(stu2);*/
//课程拥有有学生
c1.getStudents().add(stu1);
c1.getStudents().add(stu2);
c2.getStudents().add(stu1);
c2.getStudents().add(stu2);
session.save(c1);
session.save(c2);
session.getTransaction().commit();
session.close();
}1.3 加载策略
1.3.1 类级别的加载策略
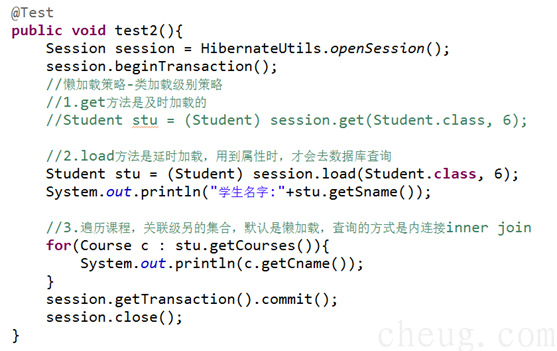
n get:立即检索。get方法一执行,立即查询所有字段的数据。
n load:延迟检索。默认情况,load方法执行后,如果只使用OID的值不进行查询,如果要使用其他属性值才查询
n 如果在类级别上配置lazy为true,那load方法就会即时加载,否则为延时加载


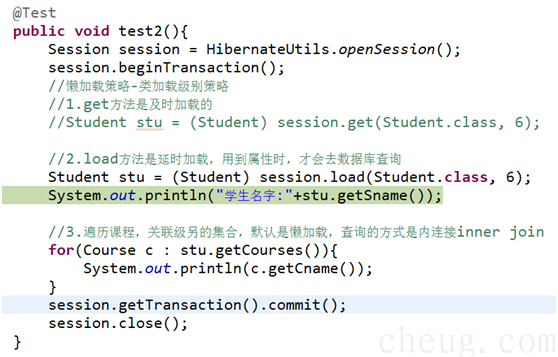
1.3.2 关联级别的加载策略
n 关联级别的集合加载的策略是默认是懒加载
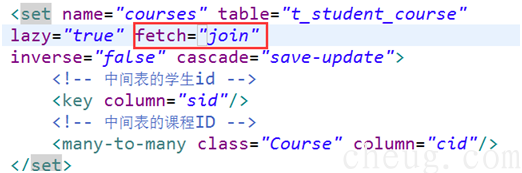
n 可以设置为即时加载,如图,即加载学生时,学生所属的课程也会加载进来

1.3.3 fecth
Fecth:拿取,获取数据
fecth:是指查询集合的sql方式
select:默认的,普通select查询语句
join:表连接语句查询
subselect:使用子查询

fetch:select
n set集合默认的sql查询方式就是fectch=select,一个普通的select查询语句
fecth:join
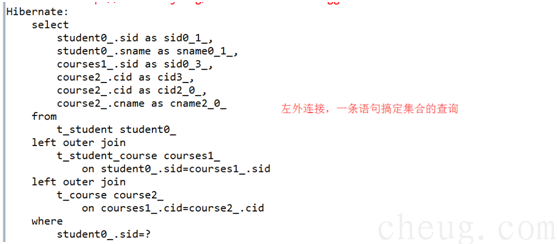
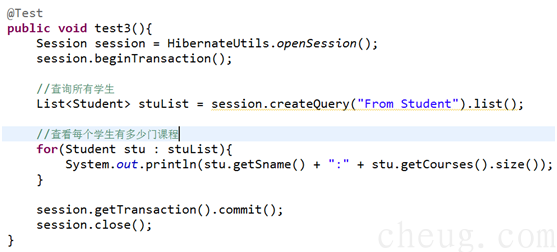
fetch:subselect
n 【只能用于多对多,一对多】

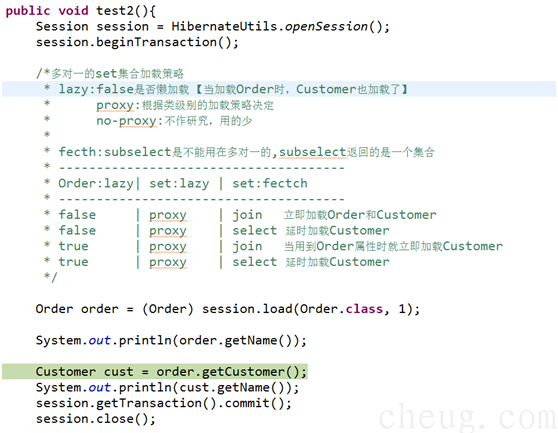
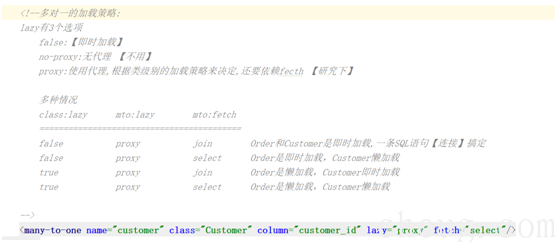
1.3.4 多对一的加载策略
² 这里以Customer和Order多例来讲解
² 多对一标签<many-to-one fetch="" lazy="">

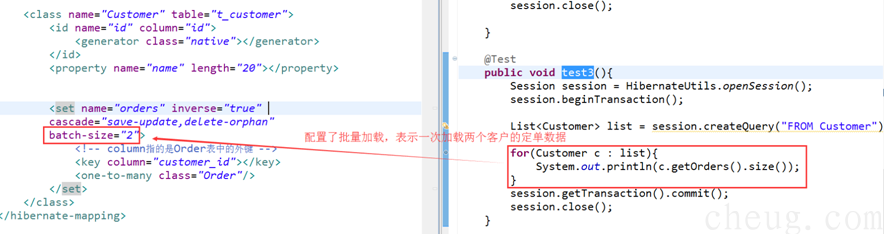
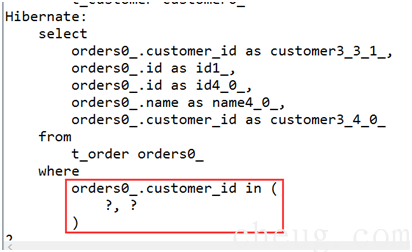
1.3.5 批量加载【了解】
set标签可以配置一个batch-size="2",表示每次可以加载两条数据
1.3.6 检索策略
检索策略 | 优点 | 缺点 | 优先考虑使用的场合 |
立即检索/ 即时加载 | 对应用程序完全透明,不管对象处于持久化状态还是游离状态,应用程序都可以从一个对象导航到关联的对象 | (1)select语句多 (2)浪费内存空间。 | (1)类级别 (2)应用程序需要立即访问的对象 (3)使用了二级缓存 |
延迟检索/ 懒加载的意思 | 由应用程序决定需要加载哪些对象,可以避免执行多余的select语句,以及避免加载应用程序不需要访问的对象。因此能提高检索性能,并节省内存空间。 | 应用程序如果希望访问游离状态的代理类实例,必须保证她在持久化状态时已经被初始化。 | (1)一对多或者多对多关联 (2)应用程序不需要立即访问或者根本不会访问的对象
|
表连接检索 | (1)对应用程序完全透明,不管对象处于持久化状态还是游离状态,都可从一个对象导航到另一个对象。 (2)使用了外连接,select语句少 | (1)可能会加载应用程序不需要访问的对象,浪费内存。 (2)复杂的数据库表连接也会影响检索性能。 | (1)多对一或一对一关联 (2)需要立即访问的对象 (3)数据库有良好的表连接性能。 |
2、HQL 查询
2.1 HQL简介
² HQL(Hibernate Query Language) 描写对象操作的一种查询语言,Hibernate特有
² HQL的语法与SQL基本一致,不同的是HQL是面向对象的查询,查询的是对象 和对象中的属性
² HQL的关键字不区分大小写,但类名和属性区分大小写
² 语法示例
SELECT 别名/属性名/表达式
FROM 实体 AS 别名
WHERE 过滤条件
GROUP BY 分组条件
HAVING 分组后的结果的过滤条件
ORDER BY 排序条件
2.2案例1:查询所有客户
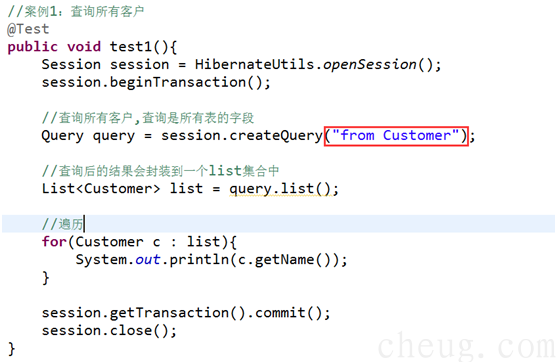
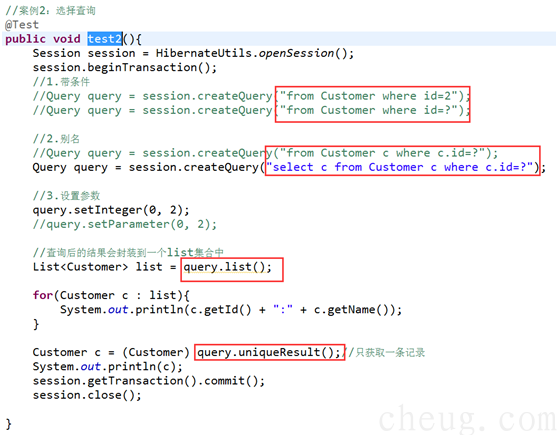
2.3 案例2:选择查询
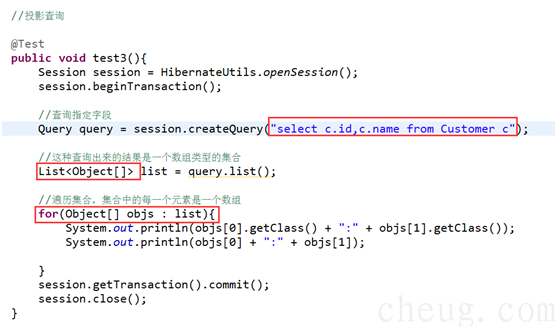
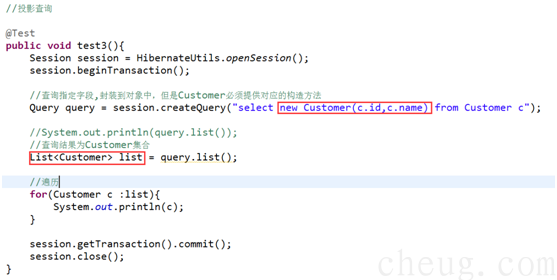
2.4 案例3:投影查询
2.5 案例4:排序

2.6 案例5:分页
Query query = session.createQuery("from Customer");
// *** pageNum 当前页(之前的 pageCode)
query.setFirstResult(0);
// * 每页显示个数 , pageSize
query.setMaxResults(2);
2.7 案例6:聚合函数和分组查询

2.8 案例7: 连接查询
INNER JOIN: 在表中存在至少一个匹配时,INNER JOIN 关键字返回行。
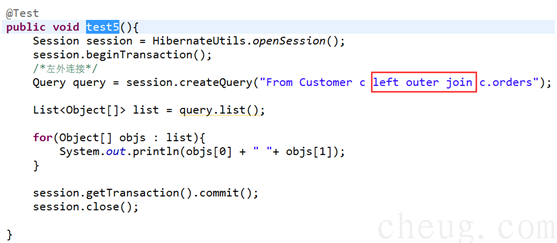
LEFT OUTER JOIN: 关键字会从左表 (table_name1) 那里返回所有的行,即使在右表 (table_name2) 中没有匹配的行
RIGHT OUTER JOIN:关键字会右表 (table_name2) 那里返回所有的行,即使在左表 (table_name1) 中没有匹配的行。
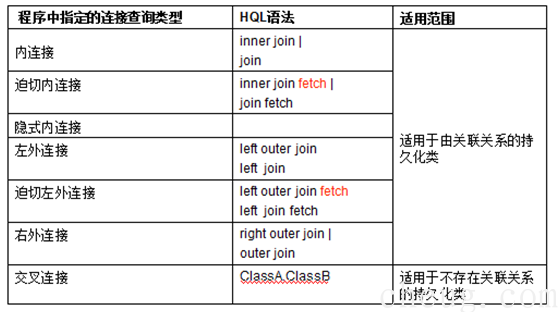
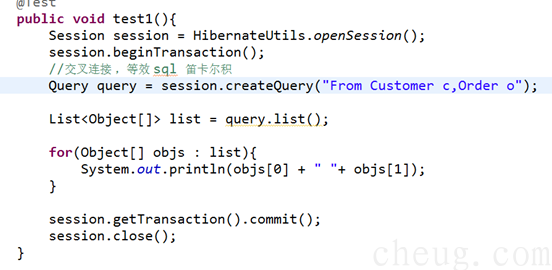
Ø 交叉连接 ,等效 sql 笛卡尔积
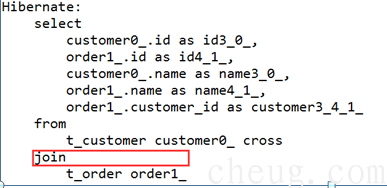
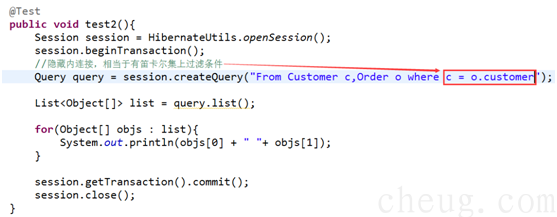
Ø 隐式内连接,等效 sql 隐式内连接
Ø 内连接,等效sql内连接
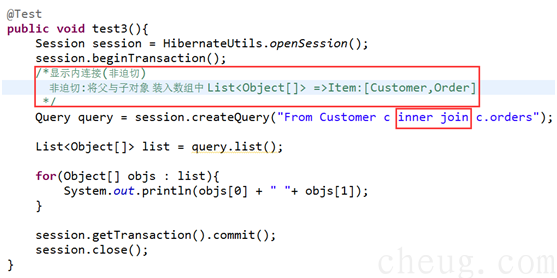
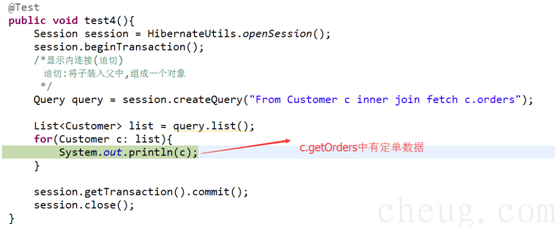
Ø 迫切内连接,hibernate底层使用 内连接。
Ø 左外连接,等效sql左外连接
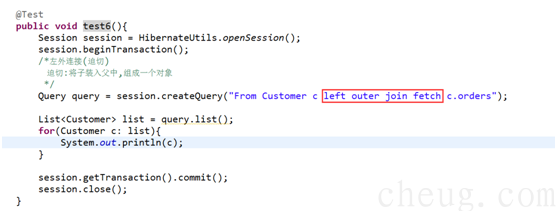
迫切左外连接,hibernate底层使用 左外连接
Ø 右外连接(迫切),等效sql右外连接

2.9 案例8: 命名查询
Ø HQL语句写在java文件里,有时候不灵活,如果要修改语句,要重新编译项目打包
Ø 我们可以在hbm.xml中命名查询语句,然后java中从hbm.xml取出hql语句,这样,以后的开发,可以直接找hbm.xml进行配置
Hbm.xml
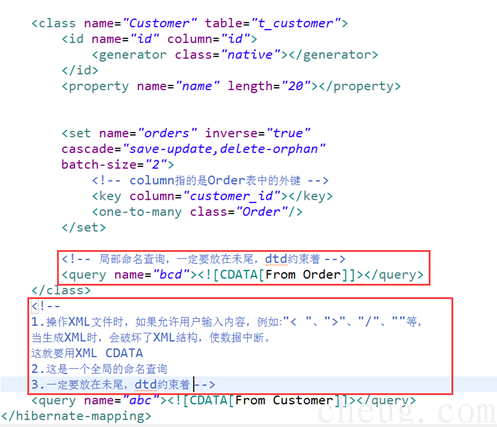
找全局的HQL,不需要指定包名 session.getNameQuery("abc")
找局部的HQL,需要指定包名 session.getNameQuery("com.cheug.domain.Customer.bcd")
3.QBC查询
3.1简介
QBC:Query By Criteria条件查询.面向对象的查询的方式.
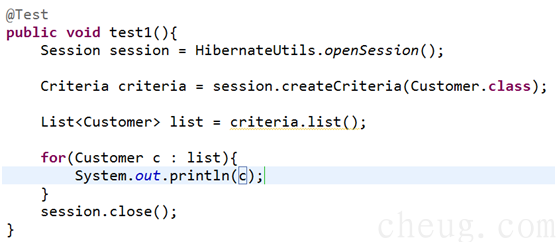
3.2 简单查询
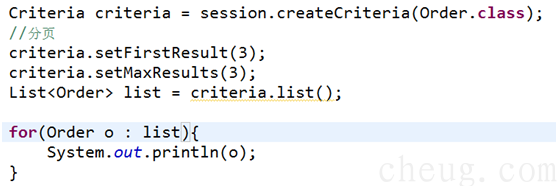
3.3 分页
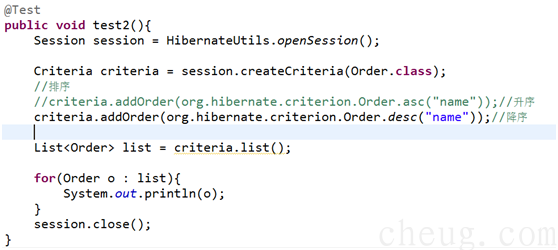
3.4 排序
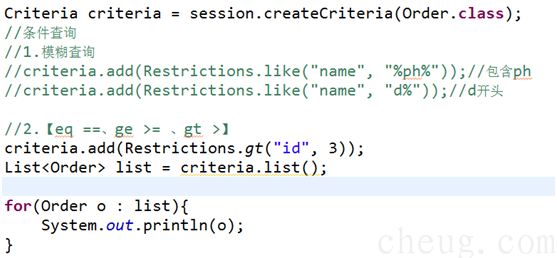
3.5 条件查询
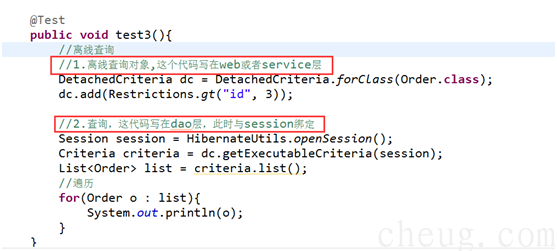
3.6 离线查询【了解】
DetachedCriteria 离线查询对象,不需要使用Session就可以拼凑查询条件。一般使用在web层或service层拼凑。将此对象传递给dao层,此时将与session进行绑定执行查询。
4.常见配置
4.1 整合c3p0连接池
第一步:把c3p0包导入工程
第二步:配置c3p0


第三步:测试
获取session并打印,如果出现下面的c3p0 pool表示配置成功

4.2 事务的隔离级别
回顾事务
一组业务操作,要么全部成功,要么全部不成功。
特性:ACID
Ø 原子性:整体 【原子性是指事务包含的所有操作要么全部成功,要么全部失败】
Ø 一致性:数据 【一个事务执行之前和执行之后都必须处于一致性状态】
Ø 隔离性:并发 【对于任意两个并发的事务T1和T2,在事务T1看来,T2要么在T1开始之前就已经结束,要么在T1结束之后才开始,这样每个事务都感觉不到有其他事务在并发地执行。】
Ø 持久性:结果 【持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的】
隔离问题
Ø 脏读:一个事务读到另一个事务未提交的内容【读取未提交内容】
在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。
Ø 不可重复读:一个事务读到另一个事务已提交的内容(insert)【读取提交内容】
这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。
Ø 虚读(幻读):一个事务读到另一个事务已提交的内容(update)
这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。
Ø Serializable(可串行化)
这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
隔离级别--解决问题
Ø read uncommittd,读未提交。存在3个问题。
Ø read committed,读已提交。解决:脏读。存在2个问题。
Ø repeatable read ,可重复读。解决:脏读、不可重复读。存在1个问题。
Ø serializable,串行化。单事务。没有问题。
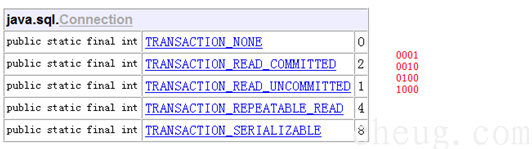
Hibernate中设置隔离级别
² 在hibernate.cfg.xml 配置hibernate.connection.isolation 4

4.3、悲观锁
悲观锁分为这面两种锁(数据库提供实现) .
读锁/共享锁 【少用】
Ø 读锁可被其他线程所共享,如果是读取的话大家都可以用这把锁读到数据.
Ø select * from table lock in share mode(读锁、共享锁)
演示步骤
A终端开事务添加读锁
B终端开事务添加读锁
A终端更新
B终端提交
A终端提交
START TRANSACTION;
#添加读锁或者共享锁,其它线程可以用这把锁
SELECT * FROM t_customer LOCK IN SHARE MODE;
#如果其它线程用了这把锁,没有提交释放锁,是不能执行更新
UPDATE t_customer SET `name` = 'guoyongfeng' WHERE id=1;
COMMIT;
写锁/排他锁【用的多】
Ø 写锁不能共享,只要有人为数据加入了写锁,其他人就不能为数据加任何锁.
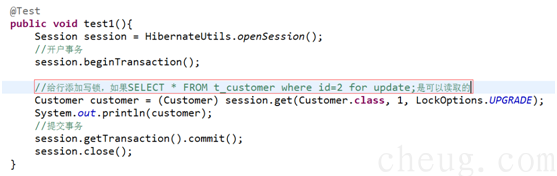
Ø select * from table for update (写锁、排它锁)
Ø 锁可以锁一张表,或者锁一行记录
演示步骤
A终端开事务添加写锁
B终端开事务读表添加写锁【读不到数据】
A终端更新
A终端提交
B终端提交
START TRANSACTION;
#给表添加写锁,其它线程无法读取这个表,当提交后才可以读取这个表
SELECT * FROM t_customer FOR UPDATE;//锁表【不推荐使用】
UPDATE t_customer SET `name` = 'guoyongfeng' WHERE id=1;
COMMIT;
演示Hibernate添加写锁
4.4、乐观锁
乐观锁就是在表中添加一个version字段来控制数据不一致性
画图,以扣钱为例
这里以Customer为例
在PO对象(javabean)提供字段,表示版本字段。一般为Integer
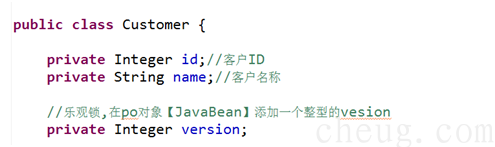
在映射文件中配置下Version

测试出结果,如果更新的版本比在数据库的版本低,就会更新出错
- 上一篇:Hibernate[二]
- 下一篇:Hibernate[四]
Powered By Cheug's Blog
Copyright Cheug Rights Reserved.